Ganzkörperkonditionierte egozentrische Videovorhersage – The Berkeley Artificial Intelligence Research Blog

Vorhersage egozentrischer Videos aus menschlichen Handlungen (PEVA). Anhand vergangener Videobilder und einer Aktion, die eine gewünschte Änderung der 3D-Pose angibt, sagt PEVA das nächste Videobild voraus. Unsere Ergebnisse zeigen, dass unser Modell bei gegebenem ersten Frame und einer Abfolge von Aktionen atomare Aktionsvideos generieren kann (a), kontrafaktische Ereignisse simulieren (b) und die Generierung langer Videos unterstützen kann (c).
Die letzten Jahre haben erhebliche Fortschritte bei globalen Modellen gebracht, die lernen, zukünftige Planungs- und Kontrollergebnisse zu simulieren. Von der intuitiven Physik bis hin zur mehrstufigen Videovorhersage sind diese Modelle immer leistungsfähiger und ausdrucksvoller geworden. Aber nur wenige sind für wirklich verkörperte Agenten konzipiert. Um ein globales Modell für verkörperte Agenten zu erstellen, benötigen wir ein real verkörperter Agent, der in der handelt real Welt. A real Der verkörperte Agent verfügt im Gegensatz zu abstrakten Kontrollsignalen über einen physisch verankerten komplexen Aktionsraum. Sie müssen auch in verschiedenen realen Szenarien agieren und eine egozentrische Sichtweise im Gegensatz zu ästhetischen Szenen und fest installierten Kameras präsentieren.

💡 Tipp: Klicken Sie auf ein beliebiges Bild, um es in voller Auflösung anzuzeigen.
Warum ist es schwierig?
- Handeln und Vision sind stark kontextabhängig. Die gleiche Vision kann zu unterschiedlichen Bewegungen führen und umgekehrt. Tatsächlich agieren Menschen in komplexen, verkörperten, zielgerichteten Umgebungen.
- Die menschliche Kontrolle ist groß und strukturiert. Die Ganzkörperbewegung umfasst über 48 Freiheitsgrade mit hierarchischer, zeitabhängiger Dynamik.
- Das egozentrische Sehen offenbart die Absicht, verbirgt aber den Körper. Die Sicht aus der ersten Person spiegelt Ziele wider, nicht jedoch die Ausführung von Bewegungen. Modelle müssen auf die Konsequenzen unsichtbarer körperlicher Handlungen schließen.
- Die Wahrnehmung hinkt dem Handeln hinterher. Visuelles Feedback kommt oft Sekunden später und erfordert langfristige Vorhersagen und zeitliche Überlegungen.
Um ein globales Modell für verkörperte Agenten zu entwickeln, müssen wir unseren Ansatz auf Agenten stützen, die diese Kriterien erfüllen. Der Mensch schaut zuerst und handelt dann: Der Blick richtet sich auf ein Ziel, das Gehirn führt eine kurze visuelle „Simulation“ des Ergebnisses durch und erst dann bewegt sich der Körper. In jedem Moment dient unsere egozentrische Vision als Input aus der Umgebung und spiegelt die Absicht/den Zweck hinter der nächsten Bewegung wider. Wenn wir die Bewegungen unseres Körpers betrachten, müssen wir sowohl die Aktionen der Füße (Fortbewegung und Navigation) als auch die Aktionen der Hand (Manipulation) oder allgemeiner die Kontrolle des gesamten Körpers berücksichtigen.
Was haben wir getan?

Wir haben ein Modell dafür trainiert P.redikieren Ezentriert sein VVorstellung von einem Menschen AFunktionen (PEVA) für die ganzkörperkonditionierte egozentrische Videovorhersage. PEVA konditioniert kinematische Posenbahnen, die durch die Gelenkhierarchie des Körpers strukturiert sind, und lernt, aus der Sicht der ersten Person zu simulieren, wie menschliche körperliche Handlungen die Umgebung prägen. Wir trainieren einen autoregressiven bedingten Diffusionstransformator auf Nymeria, einem großen Datensatz, der reale egozentrische Videos mit der Erfassung von Körperhaltungen kombiniert. Unser hierarchisches Bewertungsprotokoll testet zunehmend schwierigere Aufgaben und bietet eine umfassende Analyse der in das Modell integrierten Vorhersage- und Steuerungsfähigkeiten. Diese Arbeit stellt einen ersten Versuch dar, komplexe reale Umgebungen und verkörpertes Agentenverhalten durch Videovorhersage aus der menschlichen Perspektive zu modellieren.
Verfahren
Strukturierte Handlungsdarstellung aus Bewegung
Um eine Brücke zwischen menschlicher Bewegung und egozentrischer Sicht zu schlagen, stellen wir jede Aktion als reichhaltigen, hochdimensionalen Vektor dar, der sowohl die Dynamik des gesamten Körpers als auch detaillierte Gelenkbewegungen erfasst. Anstatt vereinfachte Steuerungen zu verwenden, kodieren wir die Gesamttranslation und die relativen Drehungen der Gelenke basierend auf dem kinematischen Baum des Körpers. Die Bewegung wird im 3D-Raum mit 3 Freiheitsgraden für die Wurzeltranslation und 15 Oberkörpergelenken dargestellt. Die Verwendung von Euler-Winkeln für relative Gelenkdrehungen ergibt einen 48-dimensionalen Aktionsraum (3 + 15 × 3 = 48). Bewegungserfassungsdaten werden mithilfe von Zeitstempeln mit dem Video abgeglichen und dann zur Positions- und Orientierungsinvarianz von globalen Koordinaten in einen lokalen, beckenzentrierten Rahmen konvertiert. Alle Positionen und Rotationen sind standardisiert, um ein stabiles Lernen zu gewährleisten. Jede Aktion erfasst Bewegungsänderungen zwischen den Bildern und ermöglicht es dem Modell, physische Bewegungen mit visuellen Konsequenzen im Laufe der Zeit in Beziehung zu setzen.
Design von PEVA: autoregressiver bedingter Diffusionstransformator
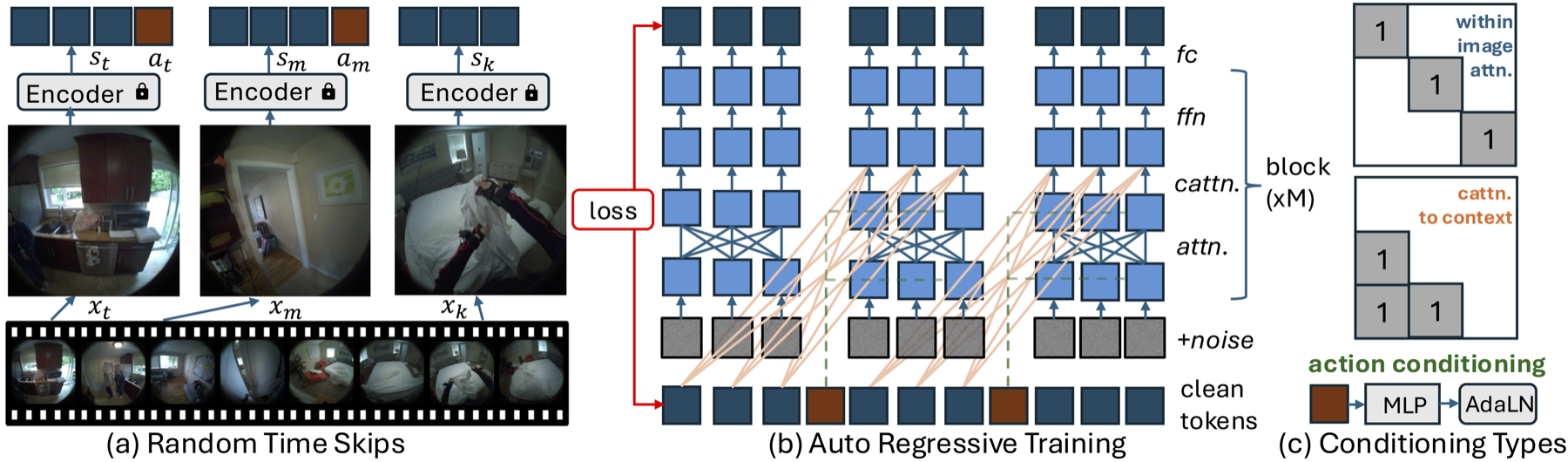
Während der Conditional Diffusion Transformer (CDiT) von Navigation World Models einfache Steuersignale wie Geschwindigkeit und Rotation verwendet, stellt die Modellierung der menschlichen Bewegung als Ganzes größere Herausforderungen dar. Menschliche Handlungen sind umfangreich, zeitlich ausgedehnt und körperlich eingeschränkt. Um diesen Herausforderungen zu begegnen, erweitern wir die CDiT-Methode auf drei Arten:
- Zufällige Zeitsprünge: Ermöglicht dem Modell, sowohl kurzfristige Bewegungsdynamiken als auch längerfristige Aktivitätsmuster zu lernen.
- Training auf Sequenzebene: Modelliert ganze Bewegungssequenzen, indem auf jedes Frame-Präfix ein Verlust angewendet wird.
- Aktionsintegrationen: Verkettet alle Aktionen zum Zeitpunkt t in einem 1D-Tensor, um jede AdaLN-Schicht für hochdimensionale Ganzkörperbewegungen zu konditionieren.
Probenahme- und Einsatzstrategie
Zur Testzeit generieren wir zukünftige Frames durch Konditionierung auf einer Reihe vergangener Kontextframes. Wir kodieren diese Frames in latenten Zuständen und fügen dem Zielframe Rauschen hinzu, das dann mithilfe unseres Diffusionsmodells schrittweise entrauscht wird. Um die Schlussfolgerung zu beschleunigen, begrenzen wir die Aufmerksamkeit, indem wir im Bild die Aufmerksamkeit nur auf das Zielbild und kontextbezogene Queraufmerksamkeit nur auf das letzte Bild richten. Für die aktionsbedingte Vorhersage verwenden wir eine autoregressive Bereitstellungsstrategie. Beginnend mit den Kontextrahmen kodieren wir diese mit einem VAE-Encoder und fügen die aktuelle Aktion hinzu. Das Modell sagt dann den nächsten Frame voraus, der dem Kontext hinzugefügt wird, während der älteste Frame entfernt wird, und der Vorgang wird für jede Aktion in der Sequenz wiederholt. Schließlich dekodieren wir die vorhergesagten Latentdaten im Pixelraum mithilfe eines VAE-Decoders.
Atomare Aktionen
Wir zerlegen komplexe menschliche Bewegungen in atomare Aktionen, wie Handbewegungen (oben, unten, links, rechts) und Ganzkörperbewegungen (vorwärts, rotieren), um das Verständnis des Modells darüber zu testen, wie sich bestimmte Bewegungen auf Gelenkebene auf das egozentrische Sehen auswirken. Wir führen hier einige Beispiele auf:
Langer Einsatz
Hier sehen Sie die Fähigkeit des Modells, die visuelle und semantische Konsistenz über erweiterte Vorhersagehorizonte hinweg aufrechtzuerhalten. Wir demonstrieren einige Beispiele von PEVA, die kohärente 16-Sekunden-Einsätze erzeugen, die durch Ganzkörperbewegungen bedingt sind. Hier finden Sie einige Videobeispiele und Beispielbilder zur weiteren Betrachtung:


Sequenz 1

Sequenz 2

Sequenz 3
Planung
PEVA kann für die Planung verwendet werden, indem mehrere Kandidatenaktionen simuliert und anhand ihrer perzeptiven Ähnlichkeit mit dem Ziel bewertet werden, gemessen durch LPIPS.

In diesem Beispiel werden Wege, die zur Spüle oder nach draußen führen, ausgeschlossen, indem der richtige Weg zum Öffnen des Kühlschranks ermittelt wird.

In diesem Beispiel werden Wege ausgeschlossen, die dazu führen, Pflanzen in der Nähe zu greifen und in die Küche zu gehen, während gleichzeitig eine vernünftige Abfolge von Aktionen gefunden wird, die zum Regal führen.
Ermöglicht visuelle Planungsfähigkeit
Wir formulieren die Planung als Energieminimierungsproblem und führen die Optimierung von Aktionen mithilfe der Kreuzentropiemethode (CEM) durch, wobei wir dem in Navigation World Models (arXiv: 2412.03572) eingeführten Ansatz folgen. Konkret optimieren wir Aktionsabläufe für den linken oder rechten Arm, während andere Körperteile fixiert bleiben. Repräsentative Beispiele der resultierenden Pläne sind unten aufgeführt:

In diesem Fall können wir eine Abfolge von Aktionen vorhersagen, die unseren rechten Arm in Richtung des Rührstabs heben wird. Wir sehen eine Einschränkung unserer Methode, da wir nur den rechten Arm vorhersagen und daher nicht vorhersagen, wie sich der linke Arm entsprechend nach unten bewegt.

In diesem Fall sind wir in der Lage, eine Handlungsfolge vorherzusagen, die sich bis zum Kessel erstreckt, ihn aber nicht ganz wie im Ziel erfasst.

In diesem Fall können wir eine Abfolge von Aktionen vorhersagen, die unseren linken Arm ähnlich wie das Ziel nach innen zieht.
Quantitative Ergebnisse
Wir bewerten PEVA anhand mehrerer Kennzahlen, um seine Wirksamkeit bei der Erstellung hochwertiger egozentrischer Videos aus Ganzkörperaktionen zu demonstrieren. Unser Modell übertrifft durchweg Benchmarks in der Wahrnehmungsqualität, behält die Konsistenz über lange Zeithorizonte bei und weist starke Skalierbarkeitseigenschaften mit der Modellgröße auf.
Grundlegende Wahrnehmungsmaße

Vergleich grundlegender Wahrnehmungsmaße zwischen verschiedenen Modellen.
Atomare Aktionsleistung

Vergleich von Modellen zur Erstellung von Atomaktionsvideos.
FID-Vergleich

FID-Vergleich auf verschiedenen Modellen und Zeithorizonten.
Skalierung

PEVA verfügt über eine gute Skalierbarkeit. Größere Modelle führen zu einer besseren Leistung.
Zukünftige Richtungen
Unser Modell zeigt vielversprechende Ergebnisse bei der Vorhersage egozentrischer Videos aus Ganzkörperbewegungen, bleibt aber ein erster Schritt in Richtung verkörperter Planung. Die Planung beschränkt sich auf die Simulation der Armbewegungen der Kandidaten und es mangelt an langfristiger Planung und vollständiger Optimierung der Flugbahn. Die Ausweitung von PEVA auf Regelkreise oder interaktive Umgebungen ist ein wichtiger nächster Schritt. Dem Modell fehlt derzeit eine explizite Konditionierung der Aufgabenabsicht oder semantischen Ziele. Unsere Bewertung verwendet Bildähnlichkeit als Proxy-Ziel. Zukünftige Arbeiten könnten von der Kombination von PEVA mit Zielkonditionierung auf hoher Ebene und der Integration objektzentrierter Darstellungen profitieren.
Danke
Die Autoren danken Rithwik Nukala für seine Hilfe bei der Kommentierung atomarer Aktionen. Wir danken Katerina Fragkiadaki, Philipp Krähenbühl, Bharath Hariharan, Guanya Shi, Shubham Tulsiani und Deva Ramanan für ihre hilfreichen Vorschläge und Kommentare zur Verbesserung des Dokuments; Jianbo Shi für die Diskussion zur Kontrolltheorie; Yilun Du für seine Unterstützung beim Broadcast-Forcing; Brent Yi für seine Unterstützung bei der Arbeit im Zusammenhang mit der menschlichen Bewegung und Alexei Efros für Diskussionen und Debatten über globale Modelle. Diese Arbeit wird teilweise von ONR MURI N00014-21-1-2801 unterstützt.
Weitere Informationen finden Sie im vollständigen Artikel oder auf der Projektwebsite.





