Meta bringt TRIBE v2 auf den Markt: ein Gehirnkodierungsmodell, das fMRT-Reaktionen auf Video-, Audio- und Textreize vorhersagt
Die Neurowissenschaften sind seit langem ein Feld des Teilens und Herrschens. Forscher ordnen typischerweise bestimmte kognitive Funktionen isolierten Regionen des Gehirns zu, wie etwa Bewegungen dem Bereich V5 oder Gesichtern dem Gyrus fusiformis, und verwenden dabei Modelle, die auf enge experimentelle Paradigmen zugeschnitten sind. Obwohl dies zu tiefgreifenden Erkenntnissen geführt hat, ist die resultierende Landschaft fragmentiert und es fehlt ein einheitlicher Rahmen, um zu erklären, wie das menschliche Gehirn multisensorische Informationen integriert.
Das FAIR-Team von Meta präsentierte sich TRIBE v2ein trimodales Gründungsmodell, das diese Lücke schließen soll. Durch den Abgleich latenter Darstellungen modernster KI-Architekturen mit der menschlichen Gehirnaktivität prognostiziert TRIBE v2 hochauflösende fMRT-Reaktionen unter verschiedenen naturalistischen und experimentellen Bedingungen.

Architektur: multimodale Integration
TRIBE v2 lernt das „Sehen“ oder „Hören“ nicht von Grund auf. Stattdessen nutzt es die Repräsentationsausrichtung zwischen tiefen neuronalen Netzwerken und dem Gehirn von Primaten. Die Architektur besteht aus drei Modellen fester Fundamente, die als dienen Feature-Extraktoren, ein zeitlicher Transformator, und a themenspezifischer Vorhersageblock.
Das Modell verarbeitet Reize über drei spezialisierte Encoder:
- Text: Kontextualisierte Integrationen werden daraus extrahiert LLaMA 3.2-3B. Für jedes Wort fügt das Modell die vorherigen 1.024 Wörter hinzu, um einen zeitlichen Kontext bereitzustellen, der dann auf ein 2-Hz-Raster abgebildet wird.
- Video: Das Modell verwendet V-JEPA2-Giant um Segmente von 64 Bildern zu verarbeiten, die sich über die letzten 4 Sekunden für jedes Zeitintervall erstrecken.
- Audio: Der Ton wird durch verarbeitet Wav2Vec-BERT 2.0mit Darstellungen, die auf 2 Hz neu abgetastet wurden, um der Reizfrequenz zu entsprechen .
2. Zeitliche Aggregation
Die resultierenden Einbettungen werden in eine gemeinsame Dimension komprimiert und zu einer multimodalen Zeitreihe mit einer Modelldimension von verkettet . Diese Sequenz wird in a eingeführt Transformator-Encoder (8 Schichten, 8 Aufmerksamkeitsköpfe), die über ein 100-Sekunden-Fenster Informationen austauschen.
3. Themenspezifische Vorhersage
Um die Gehirnaktivität vorherzusagen, werden die Transformatorausgänge auf die fMRT-Frequenz von 1 Hz dezimiert. und überquerte a Betreffblock. Dieser Block projiziert latente Darstellungen auf 20.484 kortikale Eckpunkte und 8.802 subkortikale Voxel.
Daten- und Skalierungsgesetze
Ein wesentliches Hindernis für die Kodierung des Gehirns ist die Datenknappheit. TRIBE v2 geht dieses Problem an, indem es „tiefe“ Datensätze für das Training (wobei einige Probanden über mehrere Stunden aufgezeichnet werden) und „breite“ Datensätze für die Auswertung verwendet.
- Ausbildung: Das Modell wurde anhand von 451,6 Stunden fMRT-Daten von 25 Probanden in vier naturalistischen Studien (Filme, Podcasts und Stummfilme) trainiert.
- Bewertung: Die Auswertung erfolgte anhand einer größeren Sammlung von insgesamt 1.117,7 Stunden mit 720 Probanden.
Das Forschungsteam beobachtete einen logarithmisch linearen Anstieg der Codierungsgenauigkeit mit zunehmender Menge an Trainingsdaten, ohne Anzeichen eines Plateaus. Dies deutet darauf hin, dass mit der Entwicklung von Neuroimaging-Benchmarks die Vorhersagekraft von Modellen wie TRIBE v2 weiter zunehmen wird.
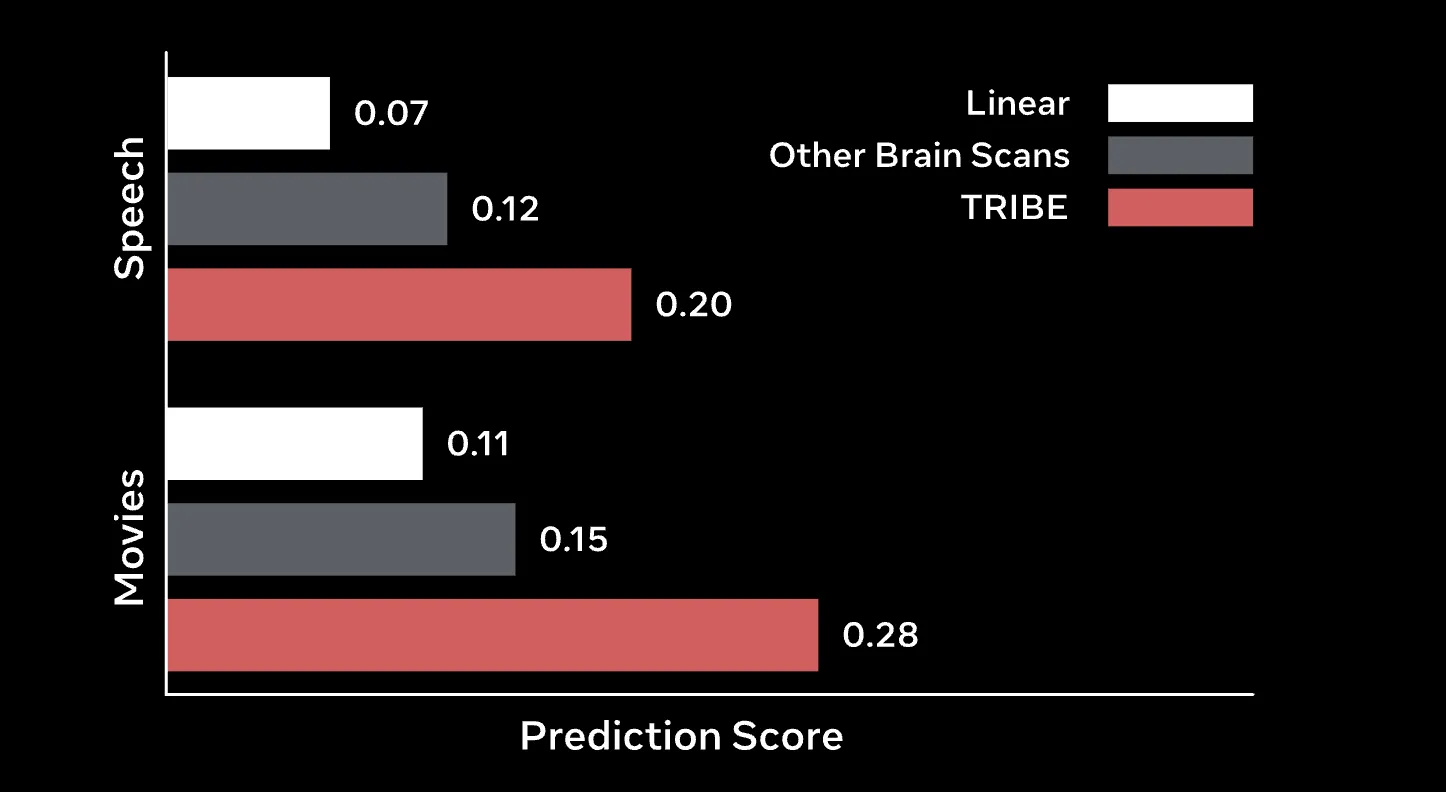
Ergebnisse: Schlagen Sie die Grundlinien
TRIBE v2 übertrifft herkömmliche Systeme deutlich Endliche Impulsantwort (FIR) Modelle, der langjährige Maßstab für die Voxelkodierung.
Zero-Shot und Gruppenleistung
Eine der auffälligsten Fähigkeiten des Modells ist Verallgemeinerung des Nullschießens zu neuen Themen. Durch die Verwendung einer Schicht „unsichtbarer Probanden“ kann TRIBE v2 die durchschnittliche Gruppenreaktion einer neuen Kohorte genauer vorhersagen, als wenn viele einzelne Probanden innerhalb dieser Kohorte tatsächlich erfasst würden. Im hochauflösenden 7T-Datensatz des Human Connectome Project (HCP) erreichte TRIBE v2 eine Gruppenkorrelation nahe 0,4, eine Verbesserung, die doppelt so groß ist wie die mittlere Gruppenvorhersage des Probanden.
Feinabstimmung
Wenn einem neuen Teilnehmer eine kleine Datenmenge (höchstens eine Stunde) zur Verfügung gestellt wird, führt die Feinabstimmung von TRIBE v2 für eine einzelne Epoche zu einer zwei- bis vierfachen Verbesserung gegenüber linearen Modellen, die von Grund auf trainiert wurden..
In-silico-Experimente
Das Forschungsteam sagt, dass TRIBE v2 nützlich sein könnte für Pilot- oder Vorscreening-Studien zur Neurobildgebung. Durch die Durchführung virtueller Experimente am Individuelles Brain Mapping (IBC) Datensatz, Das Modell hat klassische funktionale Benchmarks wiederhergestellt:
- Vision: Er lokalisierte genau den fusiformen Bereich des Gesichts (FFA) und der Parahippocampus-Locus-Bereich (APP).
- Sprache: Es gelang ihm, den temporoparietalen Übergang wiederherzustellen (TPJ) zur emotionalen Verarbeitung und Der Bezirk Broca für die Syntax.
Darüber hinaus durch Bewerbung Unabhängige Komponentenanalyse (ICA) Die letzte Ebene des Modells ergab, dass TRIBE v2 auf natürliche Weise fünf bekannte Funktionsnetzwerke lernt: primäres Hören, Sprache, Bewegung, Standardmodus und visuell..
Schlüssel zum Erinnern
- Eine leistungsstarke trimodale Architektur: TRIBE v2 ist ein Basismodell, das integriert werden kann Video, Audio und Sprache durch den Einsatz modernster Encoder wie LLaMA 3.2 für den Text, V-JEPA2 für das Video, und Wav2Vec-BERT für Audio.
- Logarithmisch-lineare Skalierungsgesetze: Genau wie die wichtigsten Sprachmodelle, die wir täglich verwenden, folgt TRIBE v2 a logarithmisch-lineares Skalierungsgesetz; Seine Fähigkeit, die Gehirnaktivität genau vorherzusagen, nimmt stetig zu, je mehr fMRT-Daten eingehen, und ein Leistungsplateau ist derzeit nicht in Sicht.
- Überlegene Verallgemeinerung von Zero-Shot: Das Modell kann die Gehirnreaktionen von vorhersagen unveröffentlichte Themen unter neuen Versuchsbedingungen ohne zusätzliche Schulung. Bemerkenswert ist, dass seine Zero-Shot-Vorhersagen bei der Schätzung der durchschnittlichen Gehirnreaktionen einer Gruppe oft genauer sind als Aufzeichnungen von einzelnen menschlichen Probanden selbst.
- Der Beginn der In-silico-Neurowissenschaft: TRIBE v2 ermöglicht „in silico“-Experimente und ermöglicht es Forschern, virtuelle neurowissenschaftliche Tests auf einem Computer durchzuführen. Er hat jahrzehntelange empirische Forschung erfolgreich reproduziert, indem er Spezialgebiete wie identifiziert hat fusiformer Gesichtsbereich (FFA) Und Der Bezirk Broca nur durch numerische Simulation.
- Neue biologische Interpretierbarkeit: Auch wenn es sich um eine Deep-Learning-„Blackbox“ handelt, sind die internen Darstellungen des Modells natürlich in fünf bekannte funktionale Netzwerke organisiert: primäres Hören, Sprache, Bewegung, Standardmodus und visuell.
Entdecken Sie die Code, Gewicht Und Demo. Folgen Sie uns auch gerne weiter Twitter und vergessen Sie nicht, bei uns mitzumachen Über 120.000 ML-Subreddit und abonnieren Unser Newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegramm erreichen.

Michal Sutter ist ein Data-Science-Experte mit einem Master of Science in Data Science von der Universität Padua. Mit einer starken Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.





