Wie rufen BM25 und RAG Informationen unterschiedlich ab?
Wenn Sie eine Suchanfrage in eine Suchmaschine eingeben, muss etwas darüber entscheiden, welche Dokumente tatsächlich relevant sind und wie sie eingestuft werden. BM25 (beste Übereinstimmung 25)Der Algorithmus, der Suchmaschinen wie Elasticsearch und Lucene antreibt, ist seit Jahrzehnten die vorherrschende Antwort auf diese Frage.
Es bewertet Dokumente anhand von drei Dingen: wie oft Ihre Suchbegriffe in einem Dokument vorkommen, wie selten diese Begriffe in der gesamten Sammlung vorkommen und wie ungewöhnlich lang ein Dokument ist. Das Schlaue daran ist, dass BM25 Keyword-Stuffing nicht belohnt: Ein 20-mal vorkommendes Wort macht ein Dokument dank der Begriffshäufigkeitssättigung nicht 20-mal relevanter. Aber BM25 hat einen grundlegenden blinden Fleck: Es findet nur die Wörter, die Sie eingegeben haben, nicht das, was Sie gemeint haben. Zur Recherche „Finde ähnliche Inhalte ohne genaue Wortüberschneidung“ und BM25 erwidert einen leeren Blick.
Das ist genau die Lücke, die Recovery Augmented Generation (RAG) mit Vektoreinbettungen wurde entwickelt, um passende Bedeutungen zu füllen, nicht nur Schlüsselwörter. In diesem Artikel erklären wir, wie jeder Ansatz funktioniert, wo jeder gewinnt und warum Produktionssysteme zunehmend beide zusammen verwenden.
So funktioniert der BM25
Im Kern weist BM25 jedem Dokument in der Sammlung für eine bestimmte Abfrage eine Relevanzbewertung zu und ordnet die Dokumente dann anhand dieser Bewertung ein. Für jeden Begriff in Ihrer Anfrage stellt BM25 drei Fragen: Wie oft kommt dieser Begriff im Dokument vor? Wie selten kommt dieser Begriff in allen Dokumenten vor? Und ist dieses Dokument ungewöhnlich lang? Der Endwert ist die Summe der gewichteten Antworten auf diese Fragen für alle Suchbegriffe.
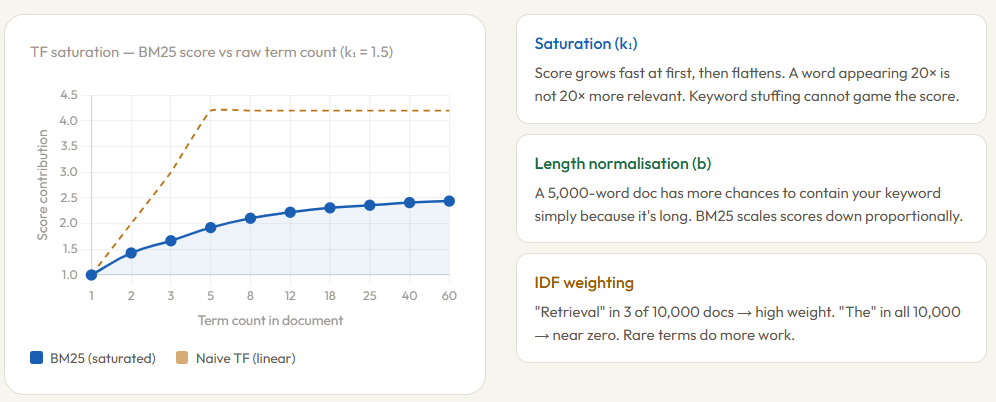
Beim Begriff Frequenzkomponente wird der BM25 smart. Dies gilt nicht für das Zählen roher Vorkommnisse, sondern für das Zählen roher Vorkommnisse Sättigung — Der Wert steigt zunächst schnell an, flacht jedoch mit zunehmender Häufigkeit ab. Ein Begriff, der fünfmal vorkommt, trägt viel mehr dazu bei als ein Begriff, der einmal vorkommt, aber ein Begriff, der 50-mal vorkommt, trägt kaum mehr bei als ein Begriff, der 20-mal vorkommt. Dies wird durch den Parameter gesteuert k₁ (normalerweise zwischen 1,2 und 2,0 eingestellt). Wenn Sie den Wert niedrig einstellen, kommt die Sättigung schnell zum Tragen. Wenn Sie den Wert hoch einstellen, ist die Rohfrequenz wichtiger. Diese einzigartige Designwahl macht den BM25 resistent gegen Keyword-Stuffing: Die hundertmalige Wiederholung eines Wortes in einem Dokument hat keinen Einfluss auf die Punktzahl.
Längennormalisierung und IDF
Der zweite Einstellparameter, B (normalerweise 0,75) steuert, wie stark die Länge eines Dokuments bestraft wird. Ein langes Dokument enthält natürlich mehr Wörter, daher ist es wahrscheinlicher, dass Ihr Suchbegriff darin enthalten ist, nicht weil er relevanter ist, sondern einfach weil er länger ist. BM25 vergleicht die Länge jedes Dokuments mit der durchschnittlichen Länge der Dokumente in der Sammlung und reduziert den Begriffshäufigkeitswert entsprechend. Einstellung b = 0 deaktiviert diese Strafe vollständig; b = 1 Wendet die vollständige Normalisierung an.
Endlich, Ausländische Direktinvestitionen (Inverse Document Frequency) stellt sicher, dass seltene Begriffe mehr Gewicht haben als häufige Begriffe. Wenn das Wort “Erholung” nur in 3 von 10.000 Dokumenten vorkommt, ist es bei Übereinstimmung ein starkes Signal für Relevanz. Wenn das Wort “DER” erscheint in den 10.000, die Korrespondenz sagt Ihnen fast nichts. Es ist IDF, das BM25 dazu bringt, auf die Wörter zu achten, die Dokumente tatsächlich unterscheiden. Ein wichtiger Vorbehalt: Da BM25 nur mit der Häufigkeit von Begriffen arbeitet, verfügt es über keine Kenntnisse über Wortreihenfolge, Kontext oder Bedeutungsübereinstimmung “Bank” in einer Frage zu Finanzen und “Bank” in einem Dokument über Flüsse sieht identisch aus mit BM25. Diese Einschränkung des Wortschatzes ist grundlegend und stellt kein Abstimmungsproblem dar.

Wie unterscheidet sich BM25 von der Vektorsuche?
BM25 und Vektorsuche beantworten die gleiche Frage: Welche Dokumente sind für diese Anfrage relevant? – aber aus grundlegend anderen Blickwinkeln. BM25 ist ein Keyword-Matching-Algorithmus: Er sucht in jedem Dokument nach den genauen Wörtern Ihrer Suchanfrage, bewertet sie anhand ihrer Häufigkeit und Seltenheit und ordnet sie entsprechend. Er hat kein Verständnis für Sprache – er behandelt den Text wie eine Tüte Chips und nicht als Bedeutung.
Die Vektorsuche hingegen wandelt mithilfe eines Einbettungsmodells sowohl die Abfrage als auch jedes Dokument in dichte numerische Vektoren um und findet dann Dokumente, deren Vektoren in die gleiche Richtung wie der Abfragevektor zeigen, gemessen anhand der Kosinusähnlichkeit. Dies bedeutet, dass die Vektorsuche übereinstimmen kann “Herzstillstand” zu einem Dokument über “Herzinsuffizienz” selbst wenn sich keines der Wörter überschneidet, da das Einbettungsmodell gelernt hat, dass diese Konzepte im semantischen Raum eng nebeneinander existieren.
Der Kompromiss ist praktisch: BM25 erfordert keine Modelle, keine GPUs und keine API-Aufrufe: Es ist schnell, leichtgewichtig und vollständig erklärbar. Die Vektorsuche erfordert ein Einbettungsmodell zur Index- und Abfragezeit, erhöht die Latenz und die Kosten und führt zu schwieriger zu interpretierenden Ergebnissen. Keines von beiden ist unbedingt besser; sie scheitern in entgegengesetzter Richtung, und genau deshalb ist Hybridforschung – die Kombination beider – zum Produktionsstandard geworden.

Vergleich von BM25 und Vektorsuche in Python
Abhängigkeiten installieren
pip install rank_bm25 openai numpyimport math
import re
import numpy as np
from collections import Counter
from rank_bm25 import BM25Okapi
from openai import OpenAIimport os
from getpass import getpass
os.environ('OPENAI_API_KEY') = getpass('Enter OpenAI API Key: ')Definieren Sie den Korpus
Bevor wir BM25 und die Vektorsuche vergleichen können, benötigen wir eine gemeinsame Wissensdatenbank, anhand derer wir suchen können. Wir definieren 12 kurze Textabschnitte, die eine Reihe von Themen abdecken: Python, maschinelles Lernen, BM25, Transformatoren, Integrationen, RAGs, Datenbanken usw. Die Themen sind bewusst vielfältig: Einige Abschnitte sind eng miteinander verbunden (BM25 und TF-IDF, Einbettungen und Kosinusähnlichkeit), während andere völlig unabhängig sind (PostgreSQL, Django). Diese Vielfalt macht den Vergleich aussagekräftig: Eine gut funktionierende Abrufmethode sollte die relevanten Blöcke aufdecken und das Rauschen ignorieren.
Dieses Korpus fungiert als Ersatz für einen echten Dokumentenspeicher. In einer RAG-Produktionspipeline würden diese Teile aus der Aufteilung und Bereinigung realer Dokumente stammen: PDFs, Wikis, Wissensdatenbanken. Hier halten wir sie kurz und handlich, damit das Genesungsverhalten leicht nachvollzogen und begründet werden kann.
CHUNKS = (
# 0
"Python is a high-level, interpreted programming language known for its simple and readable syntax. "
"It supports multiple programming paradigms including procedural, object-oriented, and functional programming.",
# 1
"Machine learning is a subset of artificial intelligence that enables systems to learn from data "
"without being explicitly programmed. Common algorithms include linear regression, decision trees, and neural networks.",
# 2
"BM25 stands for Best Match 25. It is a bag-of-words retrieval function used by search engines "
"to rank documents based on the query terms appearing in each document. "
"BM25 uses term frequency and inverse document frequency with length normalization.",
# 3
"Transformer architecture introduced the self-attention mechanism, which allows the model to weigh "
"the importance of different words in a sentence regardless of their position. "
"BERT and GPT are both based on the Transformer architecture.",
# 4
"Vector embeddings represent text as dense numerical vectors in a high-dimensional space. "
"Similar texts are placed closer together. This allows semantic search -- finding documents "
"that mean the same thing even if they use different words.",
# 5
"TF-IDF stands for Term Frequency-Inverse Document Frequency. It reflects how important a word is "
"to a document relative to the entire corpus. Rare words get higher scores than common ones like 'the'.",
# 6
"Retrieval-Augmented Generation (RAG) combines a retrieval system with a language model. "
"The retriever finds relevant documents; the generator uses them as context to produce an answer. "
"This reduces hallucinations and allows the model to cite sources.",
# 7
"Django is a high-level Python web framework that encourages rapid development and clean, pragmatic design. "
"It includes an ORM, authentication system, and admin panel out of the box.",
# 8
"Cosine similarity measures the angle between two vectors. A score of 1 means identical direction, "
"0 means orthogonal, and -1 means opposite. It is commonly used to compare text embeddings.",
# 9
"Gradient descent is an optimization algorithm used to minimize a loss function by iteratively "
"moving in the direction of the steepest descent. It is the backbone of training neural networks.",
# 10
"PostgreSQL is an open-source relational database known for its robustness and support for advanced "
"SQL features like window functions, CTEs, and JSON storage.",
# 11
"Sparse retrieval methods like BM25 rely on exact keyword matches and fail when the query uses "
"synonyms or paraphrases not present in the document. Dense retrieval using embeddings handles "
"this by matching semantic meaning rather than surface form.",
)
print(f"Corpus loaded: {len(CHUNKS)} chunks")
for i, c in enumerate(CHUNKS):
print(f" ({i:02d}) {c(:75)}...")Bau des BM25 Retriever
Sobald der Korpus definiert ist, können wir den BM25-Index erstellen. Der Prozess besteht aus zwei Phasen: Tokenisierung und Indizierung. Die tokenize-Funktion verkleinert den Text und teilt ihn in alle nicht alphanumerischen Zeichen auf – so wird „TF-IDF“ zu („tf“, „idf“) und „bag-of-words“ zu („bag“, „of“, „words“). Es ist bewusst einfach: BM25 ist ein Bag-of-Words-Modell, es gibt also keine Wortstammbildung, keine Stoppwortentfernung und keine sprachliche Vorverarbeitung. Jedes Wort wird als unabhängiges Token behandelt.
Sobald jeder Block tokenisiert ist, erstellt BM25Okapi den Index, indem es die Dokumentlänge, die durchschnittliche Dokumentlänge und die IDF-Scores für jeden eindeutigen Begriff im Korpus berechnet. Dies geschieht einmal beim Start. Zum Zeitpunkt der Abfrage tokenisiert bm25_search die eingehende Abfrage auf die gleiche Weise, ruft get_scores auf, um parallel einen BM25-Relevanzwert für jeden Block zu berechnen, sortiert dann die besten k Ergebnisse und gibt sie zurück. Die Zustandsprüfung unten führt eine Testabfrage aus, um zu bestätigen, dass der Index funktioniert, bevor er an den Integrationsabrufer übergeben wird.
def tokenize(text: str) -> list(str):
"""Lowercase and split on non-alphanumeric characters."""
return re.findall(r'\w+', text.lower())
# Build BM25 index over the corpus
tokenized_corpus = (tokenize(chunk) for chunk in CHUNKS)
bm25 = BM25Okapi(tokenized_corpus)
def bm25_search(query: str, top_k: int = 3) -> list(dict):
"""Return top-k chunks ranked by BM25 score."""
tokens = tokenize(query)
scores = bm25.get_scores(tokens)
ranked = np.argsort(scores)(::-1)(:top_k)
return (
{"chunk_id": int(i), "score": round(float(scores(i)), 4), "text": CHUNKS(i)}
for i in ranked
)
# Quick sanity check
results = bm25_search("how does BM25 rank documents", top_k=3)
print("BM25 test -- query: 'how does BM25 rank documents'")
for r in results:
print(f" ({r('chunk_id')}) score={r('score')} {r('text')(:70)}...")Aufbau des Integration Retrievers
Der Integrationskollektor funktioniert in jeder Phase anders als der BM25. Anstatt Token zu zählen, wandelt es jeden Block mithilfe des Text-Embedding-3-Small-Modells von OpenAI in einen dichten numerischen Vektor um – eine Liste mit 1.536 Zahlen. Jede Zahl stellt eine Dimension im semantischen Raum dar, und Blöcke, die ähnliche Dinge bedeuten, haben am Ende Vektoren, die in ähnliche Richtungen zeigen, unabhängig davon, welche Wörter sie verwenden.
Der Indexerstellungsschritt ruft die Integrations-API einmal pro Block auf und speichert die resultierenden Vektoren im Speicher. Dies ist der Hauptkostenunterschied im Vergleich zu BM25: Die Erstellung des BM25-Index ist reine Arithmetik auf Ihrem eigenen Computer, während die Erstellung des Einbettungsindex einen API-Aufruf pro Stück erfordert und die Vektoren erzeugt, die Sie speichern müssen. Bei 12 Stück ist das trivial; Bei einer Million Stück wird es zu einer echten Infrastrukturentscheidung.
Zum Zeitpunkt der Abfrage bettet embedding_search die eingehende Abfrage mit demselben Modell ein – das ist wichtig, die Abfrage und die Fragmente müssen sich im selben Vektorraum befinden – und berechnet dann die Kosinusähnlichkeit zwischen dem Abfragevektor und jedem gespeicherten Fragmentvektor. Die Kosinusähnlichkeit misst den Winkel zwischen zwei Vektoren: Ein Wert von 1 bedeutet identische Richtung, 0 bedeutet keine Beziehung zwischen ihnen und negative Werte bedeuten entgegengesetzte Bedeutung. Die Chunks werden dann basierend auf dieser Punktzahl eingestuft und die obersten k werden zurückgegeben. Auch hier wird die gleiche Plausibilitätsprüfungsabfrage aus Abschnitt BM25 ausgeführt, sodass Sie den ersten direkten Vergleich zwischen den beiden Ansätzen bei identischer Eingabe sehen können.
EMBED_MODEL = "text-embedding-3-small"
def get_embedding(text: str) -> np.ndarray:
response = client.embeddings.create(model=EMBED_MODEL, input=text)
return np.array(response.data(0).embedding)
def cosine_similarity(a: np.ndarray, b: np.ndarray) -> float:
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
# Embed all chunks once (this is the "index build" step in RAG)
print("Building embedding index... (one API call per chunk)")
chunk_embeddings = (get_embedding(chunk) for chunk in CHUNKS)
print(f"Done. Each embedding has {len(chunk_embeddings(0))} dimensions.")
def embedding_search(query: str, top_k: int = 3) -> list(dict):
"""Return top-k chunks ranked by cosine similarity to the query embedding."""
query_emb = get_embedding(query)
scores = (cosine_similarity(query_emb, emb) for emb in chunk_embeddings)
ranked = np.argsort(scores)(::-1)(:top_k)
return (
{"chunk_id": int(i), "score": round(float(scores(i)), 4), "text": CHUNKS(i)}
for i in ranked
)
# Quick sanity check
results = embedding_search("how does BM25 rank documents", top_k=3)
print("\nEmbedding test -- query: 'how does BM25 rank documents'")
for r in results:
print(f" ({r('chunk_id')}) score={r('score')} {r('text')(:70)}...")Parallele Vergleichsfunktion
Dies ist das Herzstück der Erfahrung. Die Vergleichsfunktion führt dieselbe Abfrage gleichzeitig über beide Abruffunktionen aus und gibt die Ergebnisse in einem zweispaltigen Layout aus – BM25 auf der linken Seite, Einbettungen auf der rechten Seite – sodass die Unterschiede sofort an derselben Rangposition sichtbar sind.
def compare(query: str, top_k: int = 3):
bm25_results = bm25_search(query, top_k)
embed_results = embedding_search(query, top_k)
print(f"\n{'═'*70}")
print(f" QUERY: \"{query}\"")
print(f"{'═'*70}")
print(f"\n {'BM25 (keyword)':<35} {'Embedding RAG (semantic)'}")
print(f" {'─'*33} {'─'*33}")
for rank, (b, e) in enumerate(zip(bm25_results, embed_results), 1):
b_preview = b('text')(:55).replace('\n', ' ')
e_preview = e('text')(:55).replace('\n', ' ')
same = "⬅ same" if b('chunk_id') == e('chunk_id') else ""
print(f" #{rank} ({b('chunk_id'):02d}) {b('score'):.4f} {b_preview}...")
print(f" ({e('chunk_id'):02d}) {e('score'):.4f} {e_preview}... {same}")
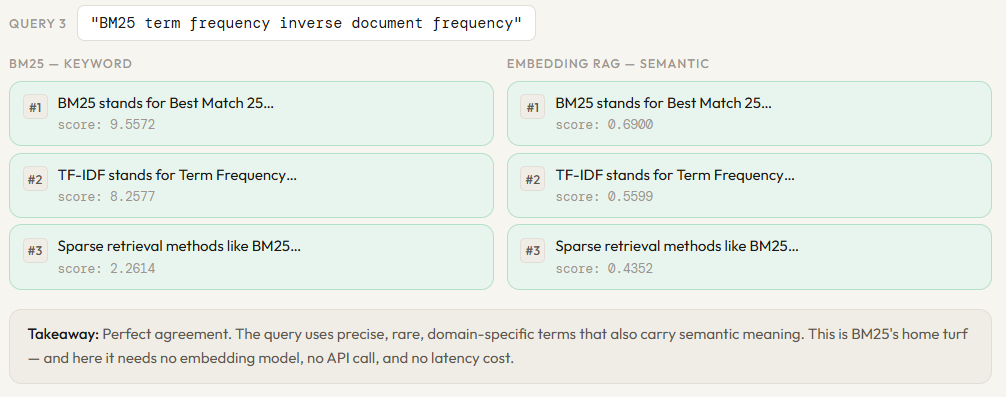
print()compare("BM25 term frequency inverse document frequency")
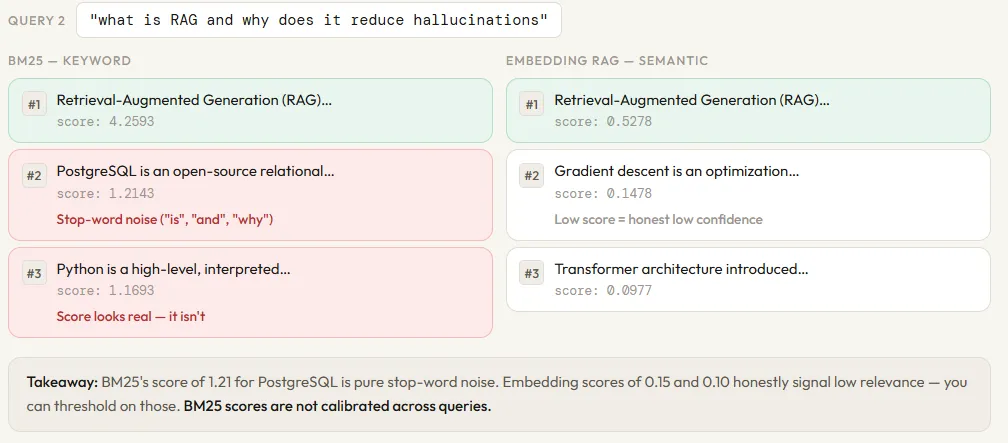
compare("what is RAG and why does it reduce hallucinations")
compare("cosine similarity between vectors")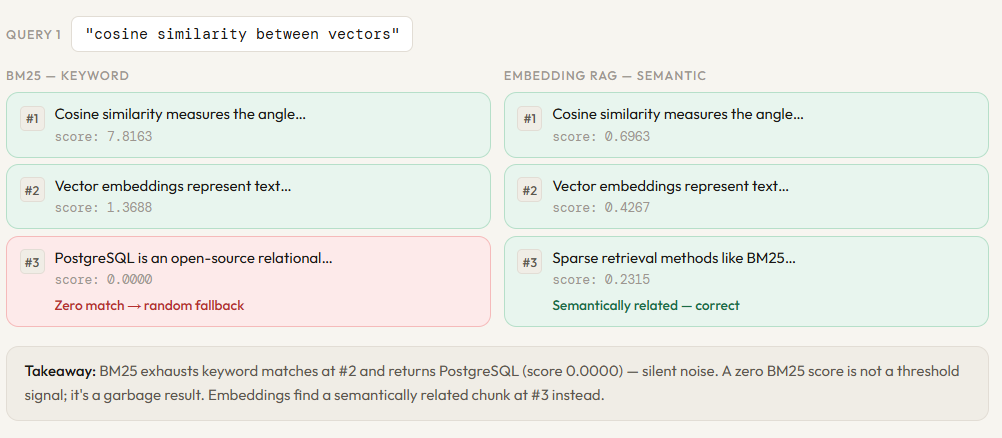

Entdecken Sie die Vollständiges Notizbuch hier. Folgen Sie uns auch gerne weiter Twitter und vergessen Sie nicht, bei uns mitzumachen Über 120.000 ML-Subreddit und abonnieren Unser Newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegramm erreichen.

Ich habe einen Abschluss in Bauingenieurwesen (2022) von Jamia Millia Islamia, Neu-Delhi, und interessiere mich sehr für Datenwissenschaft, insbesondere für neuronale Netze und deren Anwendung in verschiedenen Bereichen.

")



