Das Baidu Qianfan-Team veröffentlicht Qianfan-OCR: Ein einheitliches 4-Parameter-Dokument-Intelligence-Modell B
Baidu Qianfan-Team vorgestellt Qianfan-OCRein End-to-End-4B-Parametermodell, das entwickelt wurde, um Dokumentanalyse, Layoutanalyse und Dokumentverständnis in einer einzigen Vision-Spracharchitektur zu vereinheitlichen. Im Gegensatz zu herkömmlichen mehrstufigen OCR-Pipelines, die separate Module zur Layouterkennung und Texterkennung miteinander verketten, führt Qianfan-OCR eine direkte Bild-zu-Markdown-Konvertierung durch und unterstützt eingabeaufforderungsgesteuerte Aufgaben wie das Extrahieren von Tabellen und das Beantworten von Dokumentfragen.

Architektur und technische Spezifikationen
Qianfan-OCR nutzt die multimodale Bridging-Architektur des Qianfan-VL-Frameworks. Das System besteht aus drei Hauptkomponenten:
- Vision-Encoder (Qianfan-ViT): Verwenden Sie a Jede Auflösung Design, das Bilder in 448 x 448 Patches gruppiert. Es unterstützt Eingaben mit variabler Auflösung bis zu 4K und erzeugt bis zu 4.096 visuelle Token pro Bild, um die räumliche Auflösung für kleine Schriftarten und dichten Text beizubehalten.
- Multimodaler Adapter: Ein zweischichtiges, leichtes MLP mit GELU-Aktivierung, das visuelle Funktionen in den Einbettungsraum des Sprachmodells projiziert.
- Rückgrat des Sprachmodells (Qwen3-4B): Eine 4.0B-Einstellungsvorlage mit 36 Ebenen und einem nativen 32K-Popup. Es verwendet Grouped-Query Attention (GQA), um die KV-Cache-Nutzung um das Vierfache zu reduzieren.
Mechanismus „Layout als Gedanke“.
Das Hauptmerkmal des Modells ist Layout wie gedachteine optionale Reflexionsphase, ausgelöst durch
- Funktioneller Nutzen: Dieser Prozess stellt explizite Layout-Analysefunktionen (Elementlokalisierung und Typklassifizierung) wieder her, die in End-to-End-Paradigmen oft verloren gehen.
- Leistungsmerkmale: Bewertung am OmniDocBench v1.5 weist darauf hin, dass die Aktivierung der Denkphase einen konsistenten Vorteil gegenüber Dokumenten mit hoher „Layout-Label-Entropie“ bietet, d. h. solchen, die heterogene Elemente wie gemischten Text, Formeln und Diagramme enthalten.
- Effizienz: Begrenzungsrahmenkoordinaten werden als spezielle dedizierte Token dargestellt (
Empirische Leistung und Referenzen
Qianfan-OCR wurde sowohl anhand spezialisierter OCR-Systeme als auch anhand allgemeiner visueller Sprachmodelle (VLM) bewertet.
Dokumentenanalyse und allgemeine OCR
Das Modell belegt in mehreren Schlüsselkriterien den ersten Platz unter den End-to-End-Modellen:
- OmniDocBench v1.5: Erzielte eine Punktzahl von 93.12übertrifft DeepSeek-OCR-v2 (91,09) und Gemini-3 Pro (90,33).
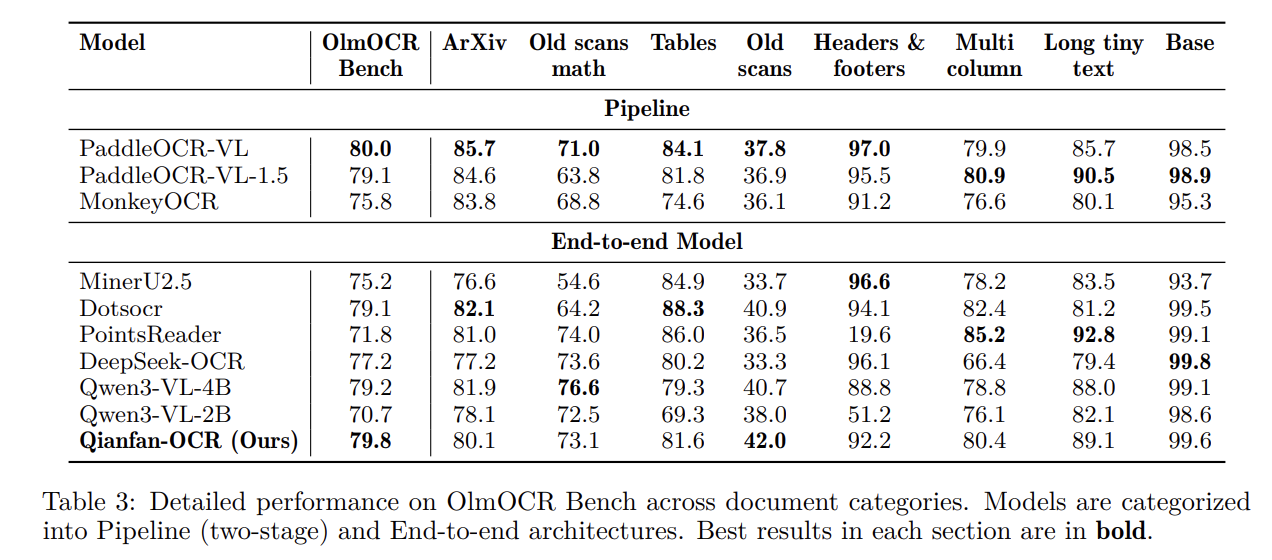
- OlmOCR-Bank: Marke 79,8Führend in der Kategorie End-to-End.
- OCR-Bank: Erzielte eine Punktzahl von 880Platz eins unter allen getesteten Modellen.
Bei öffentlichen KIE-Tests erreichte Qianfan-OCR den höchsten Durchschnittswert (87,9) und übertraf damit deutlich größere Modelle..
| Modell | Gesamtdurchschnitt (KIE) | OCRBench KIE | KIE Nanonetze (F1) |
| Qianfan-OCR (4B) | 87,9 | 95,0 | 86,5 |
| Qwen3-4B-VL | 83,5 | 89,0 | 83,3 |
| Qwen3-VL-235B-A22B | 84,2 | 94,0 | 83,8 |
| Gemini-3.1-Pro | 79,2 | 96,0 | 76.1 |
Die Dokumente verstehen
Vergleichstests ergaben, dass zweistufige OCR+LLM-Pipelines häufig bei Aufgaben versagen, die räumliches Denken erfordern. Beispielsweise haben alle getesteten zweistufigen Systeme erreicht 0,0 An CharXiv Markierungen, da in der Textextraktionsphase der visuelle Kontext (Beziehungen zwischen Achsen, Positionen von Datenpunkten) eliminiert wird, der für die Interpretation des Diagramms erforderlich ist.
Bereitstellung und Schlussfolgerung
Die Inferenzeffizienz wurde in gemessen Seiten pro Sekunde (PPS) mit einer einzelnen NVIDIA A100 GPU.
- Quantifizierung: Mit W8A8 Quantifizierung (AWQ)Qianfan-OCR durchgeführt 1.024 KKSeine 2-fache Beschleunigung gegenüber der W16A16-Basislinie mit vernachlässigbarem Genauigkeitsverlust.
- Architektonischer Vorteil: Im Gegensatz zu Pipeline-Systemen, die auf einer CPU-basierten Konfigurationsanalyse basieren, die zu einem Engpass werden kann, ist dies bei Qianfan-OCR der Fall GPU-zentriert. Dies vermeidet Verarbeitungsverzögerungen zwischen den Schritten und ermöglicht eine effiziente Schlussfolgerung bei großen Chargen.
Überprüfen Papier, Repos Und Modell auf HF. Folgen Sie uns auch gerne weiter Twitter und vergessen Sie nicht, bei uns mitzumachen Über 120.000 ML-Subreddit und abonnieren Unser Newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegramm erreichen.

Michal Sutter ist ein Data-Science-Experte mit einem Master of Science in Data Science von der Universität Padua. Mit einer starken Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.





